





Wormhole
While developing tools for NebulOS, I wrote a nifty little program that I call "Wormhole," which uses the Linux kernel's inotify functionality to react to filesystem events. More specifically, it watches a directory and performs user-specified actions on any files that are moved into or written to the directory. Once the files are processed, the results are stored in another directory. The syntax is like this:
[bash gutter="false"] $ wormhole action entrance_directory exit_directory[/bash]
where the action is either a program name or one of the built-in commands: --zip or --unzip.
The program that is used as the action must take two input arguments: an input file and an output directory. Wormhole expects the action to remove the input file from the entrance_directory as its final step. The simplest (very silly) example is:
[/bash]
In this example, the action is the move command, mv. Whenever a file is added to /directory1, it will automatically be moved to /directory2.
A more realistic use case would involve a script that performs some sort of useful operations on the files that enter the entrance_directory. Here's a slightly less silly example action:
# pdf_append.sh - A command for adding new pages to a PDF file
# usage: pdf_append.sh input_image output_directory
# where input_image is an image file that can be processed with
# ImageMagick's convert command and output_directory contains
# exactly one PDF document.
# Note that this is a very fragile script for demonstration
# purposes only.
input_image="$1"
output_dir="$2"
# convert image to PDF
# (this assumes the input is an image and isn't already a PDF)
input_pdf="$input_image.pdf"
convert "$input_image" "$input_pdf"
# get the name of the PDF being appended to.
# (this assumes that there is exactly one PDF file in output_dir)
output_pdf="$(ls $output_dir/*.pdf)"
temp_pdf="{output_pdf/.pdf/-temp.pdf}"
# append the input_pdf to the end of the output_pdf
mv "$output_pdf" "$temp_pdf"
pdfunite "$temp_pdf" "$input_pdf" "$output_pdf"
# these tools would also work to perform the join operation:
# pdftk $temp_pdf $input_pdf cat output $output_pdf
# pdfjoin $temp_pdf $input_pdf $output_pdf
# delete intermediate files and the input image:
rm "$input_image" "$input_pdf" "$temp_pdf"
[/bash]Suppose I create directories, called in/ and out/, in my current working directory. Inside of the out/ directory, I place a PDF document. I then start Wormhole, like this:
[/bash]
Now, if I save or move images into the in/ directory, they will automatically be appended to the PDF document in out/ as new pages. This is particularly handy when you use a GUI file manager to drag and drop images into in/. Adding just a few more lines of code to this example script would make it quite useful! It would also be easy to write scripts to convert and / or concatenate audio or video files, add files to an archive, or rename files based on their contents or the order in which they are added to in/. Many things are possible!
Motivation
Wormhole was initially developed to provide a means of automatically compressing files before they are sent over a non-compressed network stream (specifically, NFS), and then decompressing the files once they have been transferred. Thus, it has two built-in actions, --zip and --unzip. These actions currently use zlib to perform the compression, but they should eventually use the LZO or QuickLZ compression library, due to their superior compression speed. The input and output directories are located in RAM-backed, tmpfs file systems in order to minimize latency. The sender places files into one "mouth" of the wormhole and files are compressed and sent to the destination computer. The receiver watches the other mouth of the wormhole and decompresses files as they arrive. When transferring a single file, this is slower than simultaneously compressing, transferring, and decompressing the data stream, but it's oftentimes more efficient than sending uncompressed data over the network. It would be even more efficient if LZO or QuickLZ compression were used. Performance depends upon the compressibility of the files, the speed of the CPUs being used, the speed of the network, and the number of files being added to the input end of the wormhole at one time; adding multiple files in rapid succession allows the compression, transfer, and decompression to happen simultaneously—even though each individual file is compressed, transferred, and decompressed in three sequential steps. This is because the --zip and --unzip actions are multithreaded in such a way that multiple files can be (de)compressed at once. A future version of Wormhole may allow large files to be broken into chunks automatically so that individual files can be simultaneously compressed, transfered, decompressed, and reassembled. It may even perform the transfer itself, rather than relying upon NFS to do the transfer.
The current version of Wormhole isn't written to be a proper daemon, but it can be cheaply "daemonized" using nohup and output redirection. For example:
[/bash]
The source for the version of Wormhole described above can be found here.
A note on the advantage of compression:
Let's define 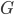 as the speedup factor gained by compressing data before transferring it to another computer:
as the speedup factor gained by compressing data before transferring it to another computer:
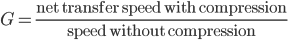
This is approximately,
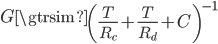
where 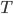 is the network throughput (the actual speed of the data transfer between the two computers),
is the network throughput (the actual speed of the data transfer between the two computers), 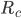 is the rate of compression,
is the rate of compression, 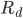 is the rate of decompression, and
is the rate of decompression, and 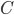 is the compression ratio:
is the compression ratio:
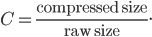
This was derived under the assumption of the worst-case scenario, in which compression, transfer, and decompression occur in three discrete steps. More realistically, the steps overlap and the speed is governed by the slowest step, so the gain is
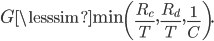
The true gain typically falls somewhere between these two formule for . Here's a plot showing the worst-case scenario gain as a function of network throughput for a file of intermediate compressibility 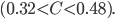 The CPU speed assumed is a 3.5 GHz Intel Core i7 (Haswell).
The CPU speed assumed is a 3.5 GHz Intel Core i7 (Haswell).

From this, it's clear that faster compression algorithms (like LZ4, LZO, QuickLZ, and Google's Snappy) perform better overall when the network throughput is high, but slower algorithms that offer more compression (like the zlib algorithm) are beneficial when the network is slower. If the network is fast enough (more than 800 MB/s or 6.4 Gbps), none of the compression schemes are beneficial for this particular file. Note that faster CPUs will push this limit higher. An optimal wormhole would be able to measure the network throughput and compression speed, then adaptively choose the best algorithm to guarantee optimal performance. Taking the compressibility of the data into account would also be beneficial because data that is not very compressible can be transferred more efficiently when no compression is used (unless the network is very slow).