





Talents
The ability to…
- learn abstract concepts quickly without being formally taught (autodidacticism).
- construct mathematical models and other logical abstractions.
- work independently without supervision or external motivators.
- clearly communicate abstract concepts and nuanced technical material to a diverse audience.
- see the ‘big picture’ and understand the fine details of a system (i.e., the forest and the trees).
- quickly identify the root causes of technical problems.
- quickly learn programming languages, APIs, frameworks, and tools.
Examples: I thought myself tensor calculus, complex analysis, galaxy dynamics, galaxy simulation techniques, as well as every programming language, API, and software application that I know.
Examples: (1) As a graduate student, I was the only person on my campus working in the field of galaxy simulation; I designed my dissertation project and performed the research independently with minimal (primarily bureaucracy-related) guidance from my advisor. (2) I have been able to solve every programming issue that I've ever encountered, by reading source code and documentation, performing experiments (debugging), examining logs, and searching the Web.
I have experience teaching and tutoring high school students, liberal arts majors, science majors, a computer engineering major, physics graduate students, and elementary school teachers. Additionally, I've written proposals targeting a variety of audiences.
My natural tendency is to think about systems as a whole. Over time, though, I have learned to enjoy thinking about smaller details and the interactions among the details which lead to complexities. When developing software from the ground up or analyzing data, one needs to be able to understand fine details while keeping things in perspective.
I am able to quickly diagnose technical problems because (1) I pay attention to small details, (2) I have a rather broad knowledge base, and (3) I have experience diagnosing problems; new problems are usually just variations of problems that I have already encountered.
A large part of my formal education and research has involved the construction of mathematical models. By “other logical abstractions,” I am referring to things like physical analogs and object-oriented and functional programming abstractions.
I can typically learn the basics of a programming language, API, or tool and begin using the new technology to write simple programs in less than a day. Depending on the complexity, fluency requires days or weeks of full-time usage and experimentation.
General
Skills
Skills
I have been writing and using object-oriented code since I began learning C++ (circa 2004). However, I only started being serious about OOP design principles in 2010.
Designing and analyzing algorithms is fun. I was formally introduced to the topic in my numerical algorithms and computational physics courses as an undergraduate. I learned more by reading, working on independent projects, participating in graduate courses, and working on research projects.
My Ph.D. and master's degree research both involved modeling and simulation. In addition to studying simulation methods and implementing those methods in code, I taught a graduate seminar in computational techniques, including simulation techniques. See the projects page for some examples.
I am familiar with the simple form of multithreading, made possible with OpenMP as well as the more flexible form, which involves mutexes, condition variables, futures, and promises.
Software Optimization: In addition to multithreading, I am familiar with cache optimization, profiling, and the explicit use of SIMD instructions on x86-64 CPUs (via compiler intrinsics). I have experience simplifying and re-designing algorithms, introducing more efficient data structures, and using approximations when they suffice. Computational / Mathematical Optimization: I am familiar with several methods of minimizing and maximizing an objective function, given constraints.
I have approximately eight years of formal research experience and I have been doing informal research for most of my life. While working on my Ph.D., I was formally recognized as the ‘best graduate student researcher’ in my class—twice.
Numerical analysis is used whenever continuous quantities need to be approximated using the discrete mathematical operations available on a digital computer. I was first introduced to the field as a sophomore in college and I have used the techniques frequently ever since.
As a scientific researcher, much of my formal training and my research has involved data analysis and interpretation.
Visualizing data is one of the easiest ways to extract insights and communicate results with others. Finding interesting ways to view data is one of the primary components of astrophysics research.
I've been trained in astronomical image processing and I am an amateur (digital) photographer who enjoys experimenting.
I have studied and used tensor calculus, vector calculus, complex analysis, ordinary and partial differential equations, linear algebra, and Fourier analysis extensively in graduate physics courses and in research. So, I am familiar with N-dimensional mathematics with arbitrary metrics, rather than just 3D Math.
I hold a terminal degree (Ph.D.) in physics. See the Education page for more details.
My Ph.D. dissertation research was in galactic astrophysics, which is a field that requires a strong foundation in astronomy. My master's degree research involved space weather modeling, which requires an understanding of astronomy on a much smaller scale.
In addition to the statistics that all physicists and astronomers are required to learn in order to do basic research, I have studied probability and statistics independently. Notably, I've studied Bayesian statistics, which is quite important in machine learning and data mining.
Teaching is one of my passions. I began tutoring calculus, physics, and astronomy in 2003. In 2005, I began teaching high school physics at one of the top-ranked public high schools in the US. Then, in 2011, I taught university physics for the first time. I've also taught basic astronomy and physics to elementary and middle school teachers, seeking a subject area (re-)certification.
Languages
C++ is currently my favorite language because of its speed and versatility. It is the only language in which I claim to be an expert. I wrote my first C++ programs in 2004, but I did not begin using the language on a regular basis until 2009. Since then, most of my projects have been primarily written in C++11.
I began using Python for data analysis, plotting, and scripting in 2010. In 2014, I used Boost::python for the first time, to integrate C++ and Python (see NebulOS).
Bash scripts are quite handy; I have written 2 – 20 Bash scripts per month, since early 2008, but I wouldn't consider myself an expert (I still frequently have to consult a reference while writing scripts).
I learned basic ECMAScript in 2013 because I wanted to use it was the scripting language for GSnap. In 2014, I learned more about how to use the language in web pages, along with the Document Object Model (DOM).
I learned the fundamentals of HTML5 in early 2014 when I began working on Pretty Parametric Plots.
I learned CSS3 in early 2014 when I learned JavaScript and HTML5.
I learned MATLAB in 2002 because it was required for my undergraduate computational physics course. I continued using MATLAB until 2008, when I completed the prototype of OpenConvection. I then began using GNU Octave, which is a free clone of MATLAB. Since 2010, I have preferred using the SciPy Python stack, rather than MATLAB, for rapid prototyping and plotting.
I learned 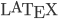 in 2007. All of my Ph.D. coursework was typeset in . Every proposal, paper, letter, and presentation that I've written since 2007 has been typeset with . My bibliographies have used
in 2007. All of my Ph.D. coursework was typeset in . Every proposal, paper, letter, and presentation that I've written since 2007 has been typeset with . My bibliographies have used 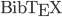 . In 2013, I learned
. In 2013, I learned 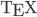 in order to customize class files.
in order to customize class files.
in 2007. All of my Ph.D. coursework was typeset in . Every proposal, paper, letter, and presentation that I've written since 2007 has been typeset with . My bibliographies have used . In 2013, I learned in order to customize class files.
In 2014, I learned the basics of Scheme in order to gain experience with a functional programming language. I chose the Guile implementation of Scheme because it is the official extension language for GNU. While it is a very interesting language, I haven't yet used it for anything other than satisfying my own curiosity.
Frameworks
& Libraries
& Libraries
Mesos is a distributed multitasking system kernel for Linux clusters (e.g., datacenters), which allows users to develop robust Big Data frameworks. It intelligently manages computational resources so that multiple frameworks can run on a datacenter simultaneously without needing to explicitly partition the datacenter.
Spark is a powerful Big Data analysis tool that I learned about while developing my own Big Data Framework, NebulOS. I have installed Spark on my Mesos cluster and taught students to use Spark at a graduate workshop on Big Data. I have not used Spark enough to become an expert, but it would be very straightforward tool to master.
LibHDFS is the C interface to the Hadoop Distributed File System. While developing NebulOS, I wrote a C++ class which wraps most of libHDFS. Thus, I've used most of the features of libHDFS.
I have used UnitTest++ to write a few unit tests and I intend to use it (or another testing tool) more often in the future. I do not currently practice test-driven development, but unit tests are nice for catching regressions.
Since 2010, I have used many GUI and non-GUI features of the Qt Framework, including the Graphics View framework and QScript.
I have used NumPy (and other components of the SciPy software stack) since 2010.
I have used Matplotlib for most of my plotting needs since 2010.
I've used quite a few of the Boost C++ libraries, including the string algorithm library, uBLAS, and Python.
I have used OpenMP to parallelize computationally expensive sections of code since 2009.
OpenCV (Open Computer Vision) is a very useful library for image and video analysis and processing. Its machine learning features are also very useful. I began experimenting with it in 2014, but I have not yet used it in an application.
SQLite is a small SQL database library that can be integrated into applications to enable database functionality. My NebulOS code uses it to cache the results of old tasks to disk in order to reduce system memory use.
The Computational Geometry Algorithms Library contains many common geometric algorithms (e.g., convex hull, mesh generation, Minkowski addition) which are very useful in scientific computing and visualization. I began experimenting with the library in 2014, but I have not yet used it in an application.
Applications
& Utilities
& Utilities
GNU Binutils are utilities for creating, manipulating, and analyzing binary programs. I have used these utilities to investigate and manipulate binaries since 2010.
I have used the GNU Compiler Collection for more than a decade, though I have only been using GCC's built-in intrinsics and attributes since 2010.
I have used the GNU debugger periodically since 2011.
I have used Git for revision control since 2011.
I have used the LLVM-based clang and clang++ compilers since 2012. Clang++ is aware of most of the non-standard, built-in functions defined by GNU C++ compiler (g++), so code written specifically for g++ often works with clang++ without modification. Additionally, clang++ sometimes produces more efficient binaries than g++.
The Valgrind suite contains debugging and profiling tools that go beyond the functionality of the standard GNU utilities. I have used the memory debugger, Memcheck, and cache profiler, Cachegrind.
Qt Creator is the official IDE for the Qt Framework; it is one of the best C++ IDEs available for GNU/Linux. I have used it since 2010.
I've used Doxygen for creating source documentation in HTML format since 2011. I have also integrated Doxygen's output with Qt Creator's help system, which makes it easy for other engineers to explore a project.
Docker is a powerful tool for containerizing software easily without the overhead of virtualization. I am familiar with creating and managing custom Docker images and managing containers that inherit from those images. However, I have not yet used Docker heavily in a production environment.
Operating Systems
Linux system administration (primarily Debian / Ubuntu)
Familiarity with Linux system calls / system programming.
Familiarity with Apache Mesos
Familiarity with Linux system calls / system programming.
Familiarity with Apache Mesos
GNU/Linux has been my primary OS at home and at work since November of 2007 (shortly after Ubuntu 7.10 was released). Over the years, I have managed several machines with multiple user accounts. In 2014, I built a small Linux cluster, for testing and developing Big Data tools. The cluster was eventually used by a few dozen people. I was the sole system administrator.
While developing NebulOS, I have needed to write Linux-specific code using many system calls such as fork, exec, pipe, wait, dup2, write, and read. I also made use of inotify in my short project, Wormhole.
Mesos is a distributed multitasking system kernel for Linux clusters (e.g., datacenters), which allows users to develop robust Big Data frameworks. It intelligently manages computational resources so that multiple frameworks can run on a datacenter simultaneously without needing to explicitly partition the datacenter. My big data framework, NebulOS, is a Mesos framework.