





Syncing VM Images Quickly (faster than rsync)
Sometimes, a trivial algorithm, when simply parallelized a bit, is much faster than a fancy algorithm that runs serially!
I recently implemented a simple algorithm for synchronizing fixed-size virtual machine images between my work laptop and desktop computer because rsync was taking several minutes to perform the task—even in cases when the disk image had barely changed. After reading a description of the rsync algorithm, it became clear why it was taking so long in this case. When operating on a single file, rsync operates in a purely serial fashion and when the single file in question is large (tens of GB), the algorithm's overhead is rather expensive, in terms of computing time and disk-reading time. See the end of this post for more details about rsync.
My simple code does the following:
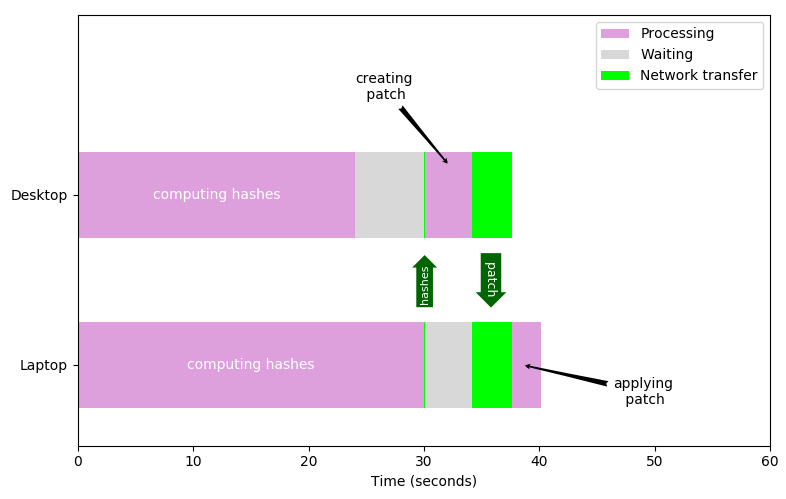
- It simultaneously computes checksums (hashes) for fixed-sized chunks of the source and distination files, so both machines read the file and compute checksums at the same time. Multiple CPU threads are used on each machine so that the file can be read at the same time that the checksums are computed; this allows the full bandwith of the storage device to be exploited, even for NVMe solid state drives.
- Sends the checksums from the destination machine to the source.
- Compares the checksums of the two files and identifies which chunks of the file changed.
- Compresses the chunks of the source file that differ from the destination, using Zstandard compression (the set of all updated chunks is called the 'patch').
- Sends the patch to the destination machine.
- Decompresses the patch on the destination machine.
- Applies the patch to the destination file.
Steps 4-7 could also be done simultaneously for different chunks of the file, but I haven't bothered to do this because the performance is already good enough for my purposes and this isn't an official project for work. The figure below shows the timing details for the process of syncing a 60 GB file using this code. The desktop was the source machine in this case. rsync requires about 8 minutes to accomplish the same task.
The code is available here. Note that it was just thrown together for my personal use, so it's not really generalized much; it's not documented particularly well, there are no tests, it does not use memory efficiently, and the transfers are all done via scp driven by the sh module in python. I would probably use ZeroMQ for communication and make steps 4-7 concurrent if this was an official project for work.
Why rsync is slow in this case
Rsync first computes checksums (hashes) of fixed-size chunks of the destination file, then it transfers the checksums to the source machine, where the checksums of the source are compared with the destination file, using sort of a 'sliding window' instead of just using chunks with pre-determined boundaries. It identifies which bytes differ between the two files and sends the differences from the source machine to the destination machine, where they are applied. It's a pretty sophisticated algorithm, which is a bit more complicated than this summary suggests, and it is quite efficient if it can be done simultaneously for many small files (i.e., a few MB or less each) because different files can be in different stages of the algorithm simultaneoulsly in different threads; the source and destination disks can work on reading and writing while the CPUs are computing checksums and data is being transferred over the network. When used to syncronize a single large file, however, the process is painfully slow; it's oftentimes comparable to simply copying the whole file from one machine to the other (assuming a 1 Gbps Ethernet link between the machines).